Processor Optimization
I implemented a processor in VHDL and then pipelined it, adding handling for branch hazards and forwarding. This write up assumes knowledge of how pipelining and forwarding and branch prediction and stuff works. It would take too long to explain all of that in detail, so I’ll save that for a textbook. Maybe I’ll do a post on it sometime to explain the high level concepts.
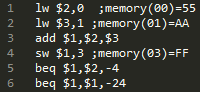
First, here’s an example that doesn’t use any pipelining or forwarding. The code executing is:
The timing diagram looks like this:
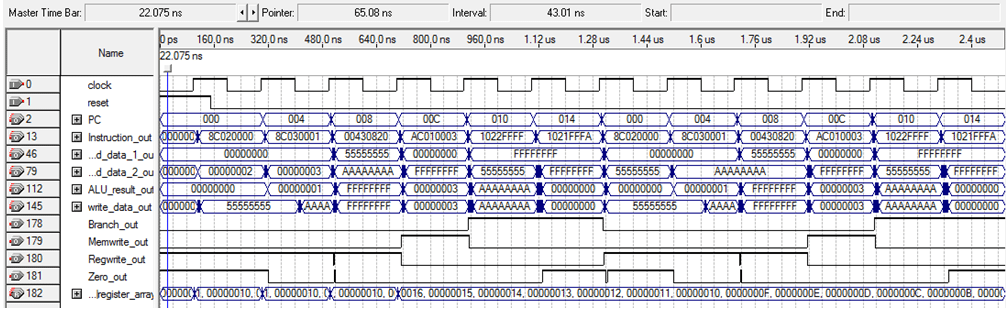
The PC keeps track of which instruction is executing. At location 000, it is executing the first lw. You can see this in the write_data_out line, since it shows the address that it is fetching. It’s storing in register 2, which can be seen in the read_data_2_out line. Similarly, the next instruction at 004 (4 bytes, or 1 word in front of the last instruction), stores the word in register 3 (seen in read_data_2_out) and is fetching from AA. The data in those 2 locations is 0 and 1, respectively. The ALU shows that. The add instruction at 008 does 0-1, which is -1, or FFFFFFFF, as seen in ALU out. Next, we store that result in memory during instruction 00C (read_data_2_out shows FFFFFFF moving). At 010, $1 and $2 are compared and found to be not equal, so we go to 014 where we find that $1 and $1 are equal. Then the PC goes back to the beginning of the instructions, the first lw instruction. From there, the whole process repeats itself.
If you zoom in on the ALU result after the 3rd instruction, you can see that it bounces around for a while before it stabilizes. This is because the way that the adder works results in the fact that different values will appear on the output while values are still sliding around and propagating through the hardware. Once it stabilizes, the value can be used. This needs to be taken into account when figuring out the maximum clock speed since taking the value too early will give you a wrong result.
Here’s a timing diagram from the pipelined processor I wrote:
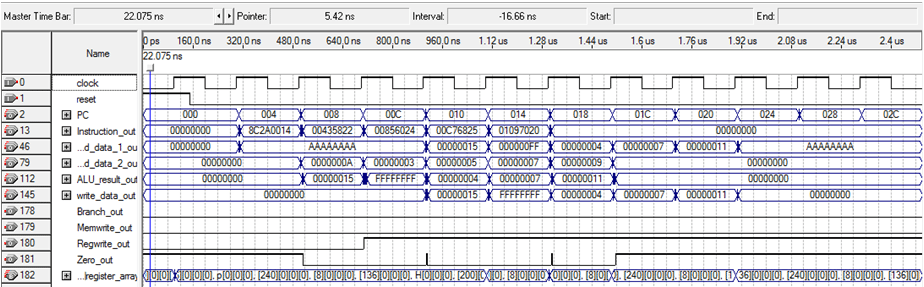
Here, you can see that starting at the second clock, the PC is incremented by 4 each time. This is also reflected below by instruction_out. You can see that each clock brings in another instruction and fills the pipeline. Read data 1 and 2 both show the output from the decode stage. ALU result shows what is coming off of the ALU and into the memory stage. Write data out can be seen waiting for an instruction that requires a write to a register before going high. Branch and memwrite are both always low because there are no branches or store words in the given instructions. Regwrite goes high one clock before write data does. You can also see where the registers are written after each instruction that writes to them.